GeneVA: A Dataset of Human Annotations for Generative Text to Video Artifacts
1New York University
IEEE/CVF Winter Conference on Applications of Computer Vision 2026
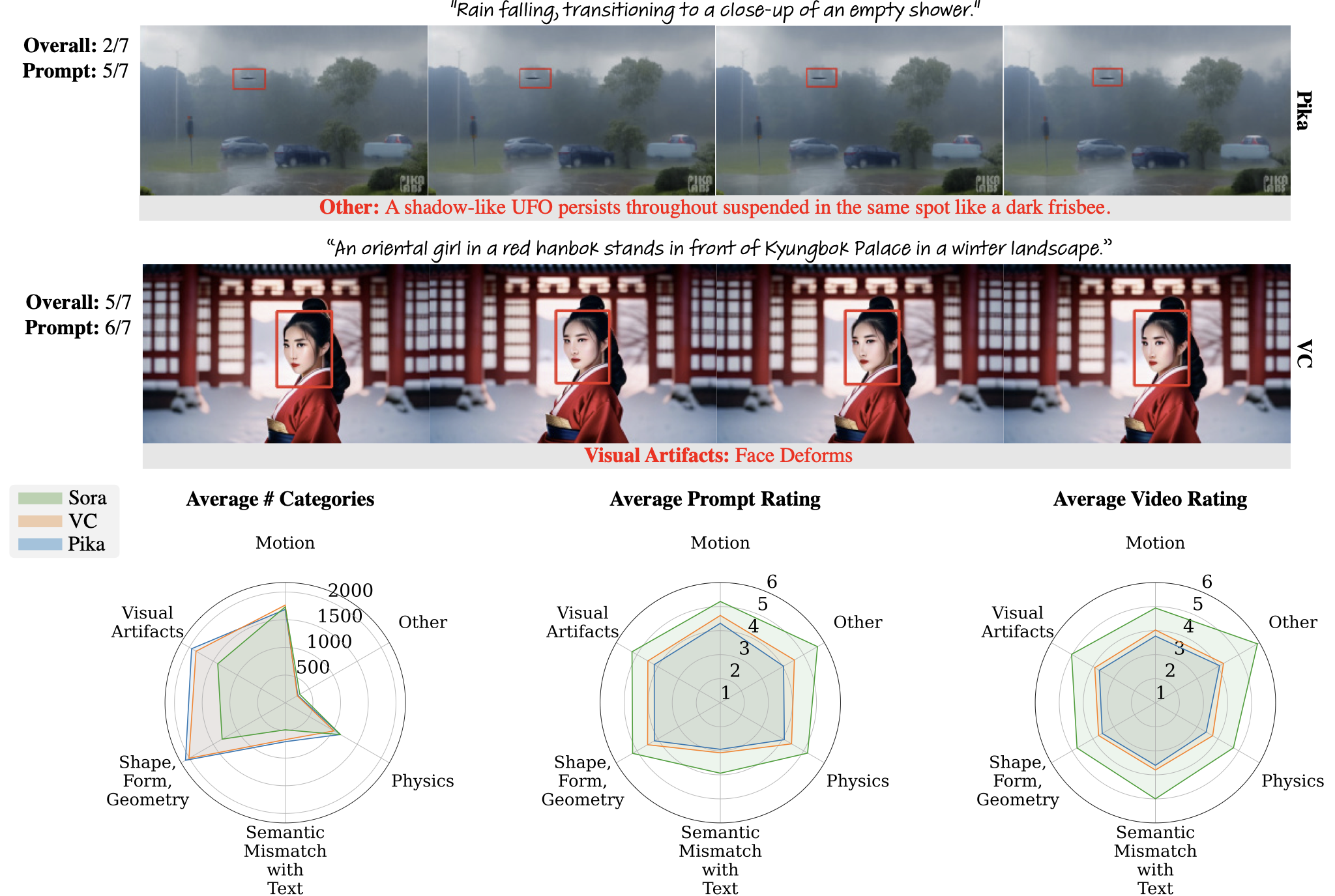
Example annotated bounding boxes and summary statistics for videos from each of the three models in our dataset (Sora, Pika, VC). The bounding boxes are annotated in red, with their artifact category and user-annotated description below the frames. Video quality ("Overall") and video-prompt alignment ("Prompt") are shown to the left.
Abstract
Recent advances in probabilistic generative models have extended capabilities from static image synthesis to text-driven video generation. However, the inherent randomness of their generation process can lead to unpredictable artifacts, such as impossible physics and temporal inconsistency. Progress in addressing these challenges requires systematic benchmarks, yet existing datasets primarily focus on generative images due to the unique spatio-temporal complexities of videos. To bridge this gap, we introduce GeneVA, a large-scale artifact dataset with rich human annotations that focuses on spatio-temporal artifacts in videos generated from natural text prompts. We hope GeneVA can enable and assist critical applications, such as benchmarking model performance and improving generative video quality.
Paper and Supplementary Materials
@article{kang2025geneva,
title={GeneVA: A Dataset of Human Annotations for Generative Text to Video Artifacts},
author={Kang, Jenna and Silva, Maria and Sangkloy, Patsorn and Chen, Kenneth and Williams, Niall and Sun, Qi},
journal={arXiv preprint arXiv:2509.08818},
year={2025}
}